글
파이썬 (Python) 리스트 (2) - 리스트 제어 함수
리스트를 만들었는데 안에 있는 데이터를 만질 일이 생길 수 있어요.
이번 편에서는 리스트 데이터를 만질 수 있는 방법 요약을 해봅시댜.
☆역순 탐색에 해당하는 -1부터 시작하는 인덱스는 (2) 편에서는 다루지 않고, 리스트 후속편에서 다루도록할게요!
☆-1 인덱스는 range와 리스트 슬라이싱과 연관이 많기떄문에, 리스트만 다루는 본 2장에서는 잠깐 패스!
1. pop() 함수 - 리스트의 데이터를 인덱스로 삭제하고, return으로 받아오는 함수입니댜.

스카피 리스트를 만들고, 하나의 백업본을 만들었는데
삭제하는 함수는 remove가 아니라 pop을 사용합니다.
remove에 대해서는 2번에서 알아볼거예요.
한번 출력해보면?

스카피 리스트의 0번 인덱스, 값이 3인 여석이 없어진 것을 확인했습니다.
1번 주제가, pop() 삭제함수는, return을 한다고 했는데 그 값도 받아오는지 확인해봐야죠?


대입/출력 코드를 합해서 테스트드라이브 결과 받아왔어요.
그럼 흔히 알고있는 remove함수와의 차이는?
2. remove() 함수 - 리스트의 데이터를 객체의 값으로 삭제합니댜
pop( index ) vs remove( value )
이것이 pop과 remove 함수의 결정적인 차이입니댜
인덱스로 리스트 데이터를 저격할 것인가, 아니면 값으로 데이터를 저격할 것인가.
우선, remove를 한번 써보고 결과를 봐보도록 하죠.
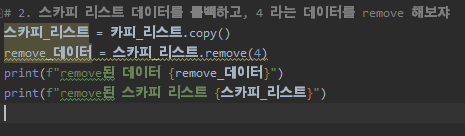

pop 데이터는 return으로 그 pop된 데이터를 들고왔지만, remove는 None을 리턴하고 있어요.
왜 값을 리턴하지 않을까?
이미 value 기준으로 값을 제거했는데, 그 삭제된 value를 다시 리턴해주는 것이 맞을까요?
인덱스로 접근시에는 그 값의 정체를 모르지만, value로 접근시에는 이미 내가 그 값의 정체를 알고 있기 때문에, 따로 value를 리턴해줄 필요는 없습니다.
None 은 흔히 다른 언어에서는 공통적으로 null value에 해당합니다. 혹은 다른 친구들과도 비교하자면, Void 객체, 대다수가 알고있는 Javascript 에서는 Undefined 객체와 비슷한 친구예요.
3. copy() 함수 - 해당 리스트 메모리에 할당된 데이터들에 대한 복제본을 만들어요
파이썬 또한 각 객체의 네이밍들은 객체, 즉 레퍼런스들입니다. C언어, C++ 등에서는 포인터로 표현되었죠. 메모리를 가리키는 주소값입니다.
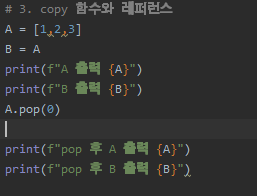
A = [1,2,3] # ... A라는 변수에 [1,2,3] 을 할당해, 그 레퍼런스를 붙였어요
B = A # ... B라는 변수에 A라는 레퍼런스를 다시 붙였어요
2개 모두 [1,2,3] 을 가리킵니다.
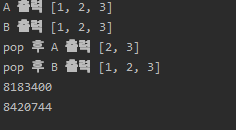
이 때, A.pop(0) 을 하고, B를 출력해볼까요?
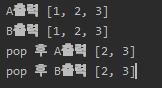
여기서 차이가 생깁니다. B와 A 모두 [1,2,3] 가 할당된 메모리 주소를 같이 가리키게 되는데, B라는 변수에 A라는 레퍼런스를 대입하며 벌어지게 된 일입니다.
위 예시 코드를 좀 더 확장해서 차이점을 볼까요? 이번엔 파이썬의 메모리 주소를 확인하는 id() 라는 함수를 써서 딥 다이브해볼거예요.
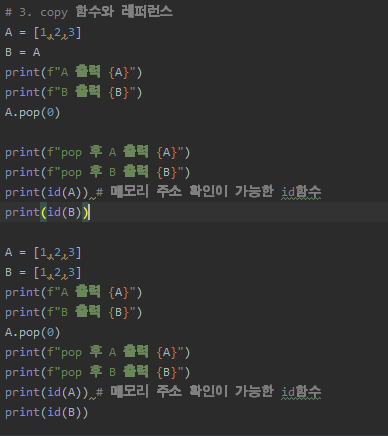

위 예시코드에, id() 를 추가했고, A = [1,2,3] B = [1,2,3] 을 따로 설정해보았어요.
보시는 바와 같이, 첫번째 B=A 는 같은 메모리주소 57400968 같은 메모리 주소를 가리키고 있네요.
A가 바라보는 57400968 메모리주소의 [1,2,3] 에서 pop을 하니, B가 바라보는 57400968 도 같이 pop이 되는 것이죠.
반대로, 아래 추가 예시코드는, A와 B 모두 [1,2,3] 따로 할당 후, A만 pop하여도 B의 데이터는 그대로 남아있죠.
아래 A와 B 추가코드의 메모리 주소도 다른 것을 확인할 수 있습니다.
먼 길을 돌아, 다시 copy 함수.... (음...)
데이터 처리 시, 원본 데이터를 한번 백업해두어야 하는 일이 있습니다.
위처럼, [1,2,3] 단순하다면 상관 없겠으나, 그게 수백건으로만 올라가도, 저렇게 하드코딩해서 대입하여 백업할 수 없는 노릇!
이 때 copy() 함수를 써서 새로운 메모리 공간을 할당해 백업해주는 좋은 꿀팁이 있어요!
방법은 간단합니다.

원하는 리스트에, copy() 함수 하나만 붙여 다른 객체에 할당해주면 끝!
결과를 보시면, pop 했는데도, B의 [1,2,3] 데이터는 그대로 남아있어요.
메모리 주소를 확인해봐도, A와 B가 같은 주소를 가졌던 것에 반해, 다른 메모리 주소가 할당된 것을 확인할 수 있죠!
copy() 함수는 유용하지만, 너무 큰 데이터를 동시에 백업할 때는, 호스팅 환경에 굉장한 부담을 줄 수 있습니다.
(어쩌다보니 카피함수와 메모리 주소, 레퍼런스의 개념까지 요약하다보니 이게 제일 길어졌댜...)
4. append() - 리스트에 데이터를 뒤에 계속 가져다 붙여놓는 함수
삭제해봤으니 추가도 해봐야죠? 리스트 뒤에 하나하나씩 데이터를 할당 생성하는 함수입니다.
쉬워요!


앙몬드 스트링 데이터를 붙여 넣으니, 스카피리스트 데이터에 잘 붙어 들어갔습니다.
remove와 마찬가지로, value 기반 호출이니, 따로 return 값이 없는 것을 볼 수 있습니다.
5. extend() - 리스트에 리스트를 붙여 확장하는 함수
append()가 단일값으로 데이터를 추가하는 함수였다면,
extend() 는 아예 리스트 자체를 덧붙여 추가하는 함수입니다.
1 vs n 의 관계라고 보면 편하겠어요!


방금 앙몬드를 append 했던 스카피리스트 자체를, 스카피리스트에 extend 하니 곱절로 불어났네요!
(앙몬드가 2명)
이번에도 리턴값은 없습니다. 함수 실행 후, 그에 대한 데이터 값은, 스카피_리스트 자체 내에 있기 때문에, 별도의 리턴값은 필요없겠죠?
6. insert() - 리스트의 특정 위치 (인덱스) 에 데이터 삽입하기 (새치기)
취소선은 그었지만.. 진짜 줄서있는 데이터 중간에 새치기해서 끼워넣기.. 라는 말이 최적 (ㅇㅈ)
특정 위치 - 인덱스에, 데이터를 끼워 넣습니다. 이 녀석은 파라미터가 2개로 지정되어 있으니, 규격을 글로 써볼게요.
리스트.insert( 인덱스-끼워넣을 위치 , 값-그 인덱스에 끼워넣을 값)
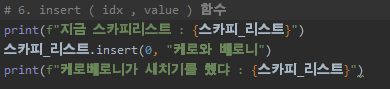

원래 스카피 리스트는 [3, 1, 2, ...., '앙몬드] 였어요.
즉, 0번 인덱스에는 3이란 값이 있었지만, 여기에 "케로와 베로니" 를 새치기시켰습니다.
원래 3이란 값은 새치기를 당해, 이제는 1번 인덱스로 가게 되었네요!
(앙몬드들도 한칸씩 밀렸다)
7. sort() & reverse() - 리스트를 순차/역순 정렬하는 함수
리스트를 보기 좋게 정렬해주는 함수입니다.
그냥 한번 둘러보시면 아 이렇구나 하고 알게 될거예요! (근데 주의하실 것도 있습니다.)


원래 숫자만 있었던 카피_리스트를 재사용해봤어요.
3,1,2,4,5 무작위였던 녀석이, sort() 하니 자동 오름차순 정렬되었어요!
아래에서는 그 카피_리스트를 reverse() 해보니 내림차순 정렬되었습니다.
근데 주의사항이 있었죠?
리스트의 정렬은 내부 타입이 일관성이 있어야 한다는 점이죠!
숫자 리스트안에 문자나, 딕트, 세트 등 동일 대상 비교가 불가한 녀석들이 섞인 잡동사니 리스트에서는 쓸 수 없다는 점 유의해두세요!
원래는 간단하게 제 자신이 까먹지 않기 위해 쓰는 글이었는데, 어느 순간부터 글이 점점 늘어가는 기이한 일이...
무튼.. 다음 편에서는 이 리스트에 대한 슬라이싱과 마이너스 인덱스, range 에 대해서 더 딥다이브를 해보도록 하죠!
'IT > Python3' 카테고리의 다른 글
| AWS EBS 네임태그 자동화 람다 (0) | 2020.08.17 |
|---|---|
| AWS ELB 네임태그 생성 자동화 스크립트 (0) | 2020.08.10 |
| 파이썬 (Python) 리스트 (3) - 리스트 슬라이싱과 역인덱스 (0) | 2020.05.18 |
| 파이썬 (Python) 리스트 (1) - 리스트를 만들어보쟈 (0) | 2020.04.15 |
| 파이썬 기초 - 콜렉션 (0) | 2020.04.13 |
